

Czas zabrać się za zrozumienie jednej z najtrudniejszych rzeczy w podstawach SQL (niezależnie od platformy) czyli inner join. W poprzednim wpisie przedstawiłem ogólny opis wszystkich rodzajów joinów, których możesz używać.
PostgreSQL Inner Join Nieco teorii…
Bez joinów możliwe jest co najwyżej pobranie danych z jednej tabeli w tym samym czasie. Mając joiny można te dane pobrać z min. 2 tabel w tym samym czasie.
W tym wpisie poznasz zasadę działania inner join, czyli pobrania części wspólnej z 2 tabel.
Zanim zaczniemy omawiać dokładniej inner join, należy wprowadzić 2 nowe pojęcia:
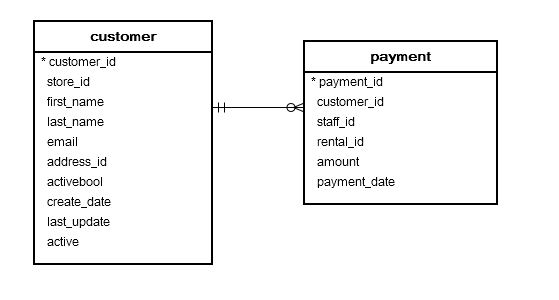
- Klucz podstawowy(główny) – określa unikalną wartość dla kolumny w tabeli. Słówko unikalny mówi o tym, że wartości w tej kolumnie nie mogą się powtarzać. Kolumna która jest kluczem głównym nie może także przechowywać wartości NULL, czyli wartości nieokreślonych/nieznanych. W jednej tabeli może być tylko jedna kolumna będąca kluczem głównym. Z mojej dotychczasowej praktyki z bazami danych wynika, że zdecydowana większość tabel powinna mieć klucz główny, z reguły ustawia się go na kolumnę ID, aby to cyfry/liczby dawały poczucie unikalności.
- Klucz obcy – służy do definiowania relacji między tabelami. Kolumnę (lub kolumny) którą zdefiniujemy jako klucz obcy w jednej tabeli wiążemy z kolumną (kolumnami) która jest kluczem głównym w drugiej tabeli. Oznacza to, że wartości przechowywane w kolumnie która jest zdefiniowana jako klucz obcy w pierwszej tabeli zawsze będą miały swój odpowiednik w kolumnie która jest zdefiniowana jako klucz główny w drugiej tabeli.
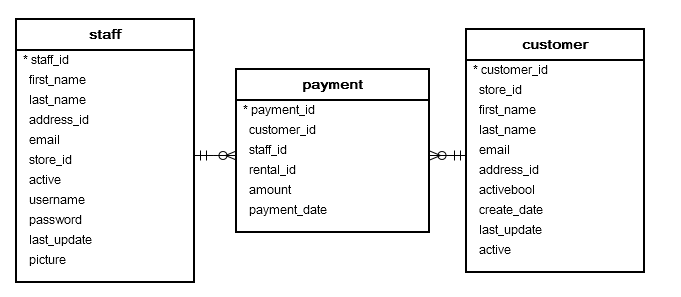
Poniżej dwie tabele, które opisują w/w zagadnienia. Klucze główne oznaczone są *, natomiast jak widzisz w tabeli payment znajduje się dodatkowa kolumna customer_id, która jest w tym przypadku kluczem obcym, który posłuży do utworzenia inner join i połączenia tych 2 tabel.
Poniżej schemat użycia inner joina.
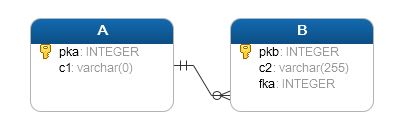
I teraz przeanalizuj użycie.
|
1 2 3 4 5 6 7 8 |
SELECT A.pka, A.c1, B.pkb, B.c2 FROM A INNER JOIN B ON A.pka = B.fka; |
Schemat jest raczej prosty:
- W klauzuli SELECT pobierasz interesujące Cię kolumny z obydwu tabel,
- Następnie po klauzuli FROM wskazujesz nazwę głównej tabeli,
- Na koniec łączysz dwie tabele za pomocą klucza głównego z pierwszej oraz obcego z drugiej tabeli.
Następnie zapytanie skanuje każdy wiersz z tabeli A i próbuje dopasować wiersze z tabeli B, które zgodne są z warunkiem A.pka = B.fka. Po odnalezieniu takiej prawidłowości scala wynik i wyświetla go w edytorze. Klucze, główny oraz obcy są opcją indeksowania danych, możesz na ten moment wyobrazić sobie, że index to taki spis treści w książce, który pomaga w szybszym znalezieniu danych. Więcej o indeksach w późniejszych wpisach.
Warto również wiedzieć w jaki sposób rozwiązać problem, gdy w tabelach, które chcemy połączyć znajdują się identyczne nazwy kolumn (szczerze powiedziawszy jest to jednak ułatwienie), wtedy ich nazwy musisz poprzedzić nazwą kolumny, aby zachować jednoznaczność .
Przykłady, przykłady…
Przejdź teraz do przykładów, które powinny rozjaśnić nieco sprawę użycia inner join.
Załóżmy, że musisz wyciągnąć z bazy dane transakcji klientów, pobierając ich id, imię, nazwisko,email, kwotę,datę płatności. W tym przypadku dane te są zgodne ze schematem z lekcji 3.
Poniżej gotowe zapytanie, które pobierze niezbędne dane. Widzisz zapewne w klazuali SELECT c oraz p, które poprzedzają nazwy kolumn – customer oraz payment. Jest to jawne wskazanie kolumn z których tabele bierzesz do scalenia. Ułatwia to nieco zrozumienie co skąd się bierze no i nieco krócej się pisze.
|
1 2 3 4 5 6 7 8 9 10 |
SELECT c.customer_id, c.first_name, c.last_name, c.email, p.amount, p.payment_date FROM customer c INNER JOIN payment p ON p.customer_id = c.customer_id |
W wyniku zapytania otrzymasz wszystkie niezbędne dane, które opiszą klienta wraz z jego płatnościami. Dane są nieco poszatkowane, natomiast w dalszych lekcjach nauczysz się jak nimi zarządzać w bardziej elastyczny sposób.
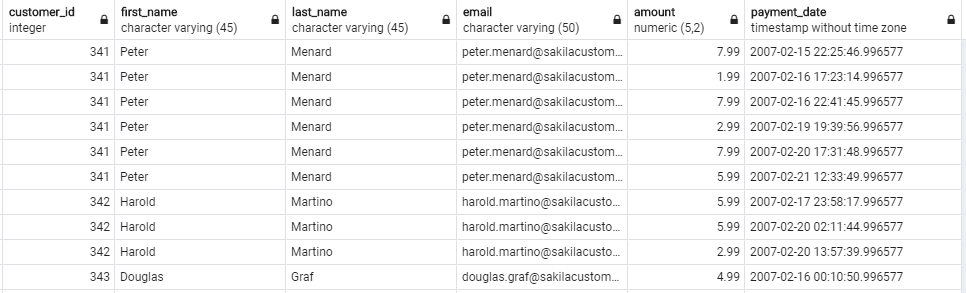
Na teraz możesz użyć klauzuli ORDER BY, w celu posortowania danych, którą już znasz.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT c.customer_id, c.first_name, c.last_name, c.email, p.amount, p.payment_date FROM customer c INNER JOIN payment p ON p.customer_id = c.customer_id ORDER BY c.customer_id |
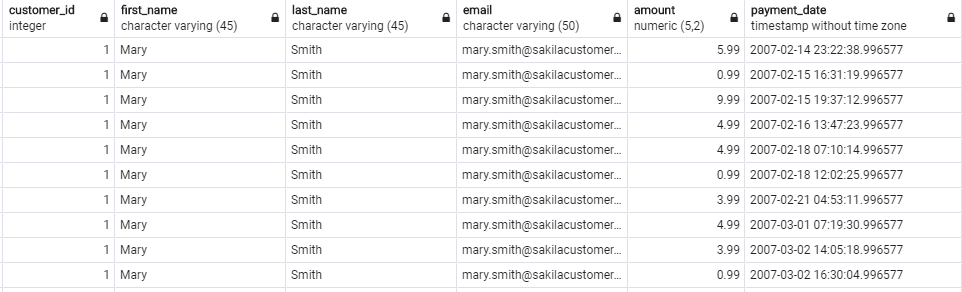
I masz w ten sposób posortowane dane po ID klienta.
Kolejnym przykładem jest możliwość zawężenia danych do tych, które są dla Ciebie ważne. Załóż, że potrzebujesz pobrać dane dla klienta o ID 300. W tym przypadku, będzie potrzebne użycie klauzuli WHERE.
|
1 2 3 4 5 6 7 8 9 10 11 |
SELECT c.customer_id, c.first_name, c.last_name, c.email, p.amount, p.payment_date FROM customer c INNER JOIN payment p ON p.customer_id = c.customer_id WHERE c.customer_id=300 |
Na koniec potwór – czyli w jaki sposób połączyć 3 tabele?
Ponownie ustawiasz domyślną tabelę jako customer, następnie wykonujesz inner join z tabelą bezpośrednio połączoną do tej domyślnej(czyli w tym przypadku payment). Następnie trzecią tabelę(staff) dołączasz w kolejnym kroku do tabeli(payment), która jest bezpośrednio połączona z główną tabelą. Same warunki po ON można zamieniać miejscami.
|
1 2 3 4 5 6 7 8 9 10 11 12 13 |
SELECT c.customer_id, c.first_name customer_first_name, c.last_name customer_last_name, c.email, s.first_name staff_first_name, s.last_name staff_last_name, p.amount, p.payment_date FROM customer c INNER JOIN payment p ON p.customer_id = c.customer_id INNER JOIN staff s ON p.staff_id = s.staff_id; |
W wyniku otrzymasz połączenie 3 różnych tabel.
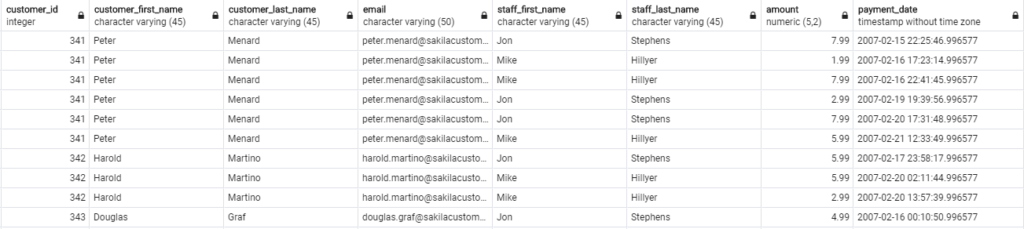
Uff, to na tyle jeżeli chodzi o przykłady powiązane z inner join. W kolejnym wpisie pokaże w jaki sposób korzystać z Full Outer Join.
Dziękuję Ci, za poświęcony czas na przeczytanie tego artykułu. Jeśli był on dla Ciebie przydatny, to gorąco zachęcam Cię do zapisania się na mój newsletter, jeżeli jeszcze Cię tam nie ma. Proszę Cię także o “polubienie” mojego bloga na Facebooku oraz kanału na YouTube – pomoże mi to dotrzeć do nowych odbiorców. Raz w tygodniu (niedziela punkt 17.00) otrzymasz powiadomienia o nowych artykułach / projektach zanim staną się publiczne. Możesz również pozostawić całkowicie anonimowy pomysł na wpis/nagranie.
Link do formularza tutaj: https://beitadmin.pl/pomysly
Pozostaw również komentarz lub napisz do mnie wiadomość odpisuję na każdą, jeżeli Masz jakieś pytania:).
