

Przyszedł szef, do którego przyszedł klient z projektem.
Pojawił się klient, który chce zbudować u nas infrastrukturę opartą o chmurę publiczną. Poza rzeczami oczywistymi czyli panowaniem nad kosztami oraz bezpieczeństwem chce tego czego „zwykła” infrastrukutra mu nie daje (przynajmniej niezbyt łatwo i szybko), czyli… skalowanie. Obecna infrastruktura nie daje rady, trzeba ją skonfigurować od nowa. Po tym zabiegu ma wytrzymać obciążenie do 1 mln użytkowników każdego miesiąca, ale z założeniem automatycznego dostosowywania pod nagłe piki przed dniami takimi jak Black Friday czy świętami Bożego Narodzenia.
Aha, pojawiła się bladość na twarzy kilku osób, ale jak to zrobić? Właśnie w tym wpisie chciałbym przedstawić idee, które mogą być w tym pomocne.
Możliwości chmury publicznej
Zaczynając od początku, chmura publiczna daje więcej niezależności oraz elastyczności. Pozwala również w stosunkowo krótkim czasie zwiększyć zasięgi działań organizacji. Jak myślisz, aplikacja będzie działać szybciej będąc w Polsce gdy klienci znajdują się w USA czy Japonii? Czy jednak lepszym rozwiązaniem będzie umiejscowienie aplikacji blisko klienta? Chcesz mieć wygodę dostępu do aplikacji z każdego urządzenia od tak, czy jednak lepsza będzie rzeźba w ustawieniach? Potrzebujesz automatycznie rozpoznawać region oraz klienta i dać mu odpowiedni jej widok? Chcesz zablokować dostęp do aplikacji dla konkretnych regionów? To tylko kilka z możliwości.
A teraz najlepsze, nie martwisz się, że coś nie działa, przy dobrze skonfigurowanej infrastrukturze awarie powodują minimalne przestoje, które potrzebne są do automatycznej odbudowy zasobów. Tyle w najgorszym wypadku, w najlepszym nastąpi chwilowe spowolnienie działania aplikacji.
Najprostsza w pełni funkcjnonalna w założeniach aplikacja widoczna jest na poniższym screenie.
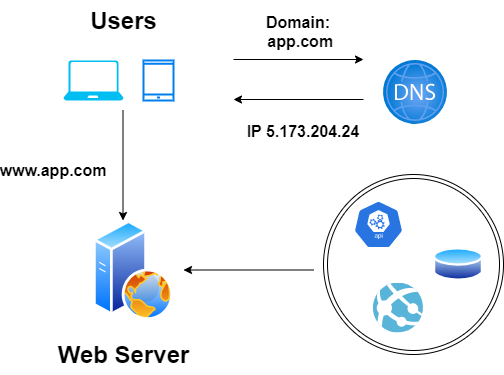
Do działania potrzebne są tylko 3 elementy. Oczywiście aplikacja bez użytkowników nie będzie nikomu potrzebna. Kolejnym elementem jest serwer www, który składa się z usługi www, bazy danych oraz opcjonalnie API, które pozwala na rozszerzenie jej funkcjonalności. Ostatnim elementem jest usługa DNS, czyli translacja adresów www.app.com na adres IP oraz utrzymywanie samej domeny pod którą działa aplikacja.
Utworzenie tak prostej struktury w fizyczne lokalizacji wymaga trochę czasu. W chmurze całą konfigurację można zrobić przy pomocy skryptów PowerShell, CLI czy Terraform no i może z małą domieszką Ansible znacznie szybciej.
W powyższym schemacie jest kilka problemów. Pierwszym jest ewentualne uszkodzenie bazy danych, usługi www. W takim przypadku dostęp do aplikacji będzie niemożliwy, ponieważ każda z tych usług występuje pojedynczo. Jak rozwiązać tego typu problemy?
Skalowanie zasobów chmury publicznej
Na początek słów kilka o skalowaniu. W chmurze takiej jak Microsoft Azure dostępne są dwa typu skalowania:
- Scale-up – ten typ skalowania polega na dodaniu zasobów do jednego serwer lub maszyny wirtualnej. Zasobami są pamięć RAM, rdzeń procesora czy też przestrzeń dyskowa. Takie podejście nazywane jest „vertical scaling„.
- Scale-out – jeżeli dodanie zasobów wyczerpało swoje możliwości, pozwala na dodanie kolejnych serwerów czy też maszyn wirtualnych do zestawu skalowalnego. To podejście nazywane jest „horizontal scaling„
Scale-up
Poniżej kilka przykładów skalowania tego typu:
- Zwiększenie pojemności we/wy (I/O) przez dodanie większej liczby dysków twardych w macierzach RAID.
- Skrócenie czasu dostępu do we/wy (I/O) dzięki przejściu na dyski półprzewodnikowe (SSD).
- Przejście na serwer z większą liczbą procesorów.
- Poprawa przepustowości sieci poprzez modernizację interfejsów sieciowych lub instalowanie dodatkowych.
- Zmniejszenie operacji we/wy (I/O) poprzez zwiększenie pamięci RAM.
Vertical scaling jest dobrą opcją dla małych systemów, które pozwlają na tanią modernizację sprzętu, ale ma również poważne ograniczenia:
- „Nie da się dodać nieograniczonej mocy do jednego serwera”. Zależy to głównie od systemu operacyjnego i jego możliwości sprzętowo/konfiguracyjnych.
- Kiedy aktualizujemy pamięć RAM do systemu, musimy wyłączyć serwer, więc jeśli system ma tylko jeden serwer, przestój jest nieunikniony.
- Wydajne maszyny zazwyczaj kosztują dużo więcej niż popularny sprzęt.
Dodanie kolejnego serwera do skalowania
Wyczerpanie możliwości dodawania zasobów wymusi dodanie kolejnych mserwerów czy też maszyn wirtualnych. Chociaż warto wcześniej prześledzić czy źle napisana aplikacja nie powoduje wycieków pamięci czy poprawnie zostały napisane zapytania do bazy. Jeżeli faktycznie zasoby są potrzebne, warto rozważyć jeszcze inne podejście, czyli rozłożenie instancji aplikacji oraz bazy na różne maszyny.

Taka architektura ma kilka zalet:
- Serwer WWW można dostroić zasobowo inaczej niż serwer bazy danych.
- Serwer WWW potrzebuje lepszego procesora, a serwer bazy danych korzysta z większej ilości pamięci RAM oraz odpowiednio wydajnych dysków.
- Korzystanie z oddzielnych serwerów dla warstwy www i warstwy danych umożliwia ich niezależne skalowanie.
Scale-out
Dodatkowe zasoby w postaci kolejnych maszyn kosztują więcej, szczególnie gdy stoi w fizycznej lokalizacji. Jak jest w chmurze? Tutaj nie ma to znaczenia. Zasoby potrzebne na 10 minut, dzień czy tydzień? Zero problemów, kwestia odpowiedniej konfiguracji. Gdy zasoby nie będą potrzebne środowisko samo je usunie. Usuwanie jest niewidoczne dla użytkownika, ma jedynie wpływ na wydatki.
W takim podejściu istotne jest również, aby aplikacja po rozszerzeniu środowiska również na nowym zasobie się pojawiła.
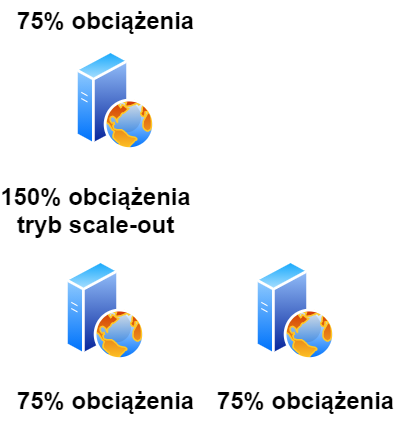
Powyżej przykład wzrostu obciążenia. Aplikacja „normalnie” nie przetracza 75% obciążenia zasobów. Jednak po uruchomieniu aplikacji na kolejnym rynku, w pewnym momencie pojawił się skokowy wzrost zapotrzebowania na zasoby. Aplikacja została do tego przygotowana, środowisko zauważyło, że metryki związane z procesorem, ramem oraz dyskiem przekroczyły limity. Zapotrzebowanie nie spadło po kolejnych 5 minutach, triggery wymusiły scale-out na kolejną maszynę. System odzyskał równowagę i ponownie wykorzystanie zasobów nie przekracza 75% na każdej z maszyn.
Po kilku dniach ruch się ustabilizował, metryki zauważyły, że obciążenie sumaryczne nie przekracza 75%, więc kolejne triggery został wywołane i usunęły drugą maszynę, aby nie generować kosztów.
Load balancer
Powyższe dwa typy skalowań są ok, ale nie są idealne, ponieważ mogą zdarzyć się przestoje w serwerowniach, chociaż mechanizmy takie jak domain update lub domain fault powinny przed tym chronić. Inne możliwości? Dodanie do struktury dodatkowego klocka czyli load balancera.
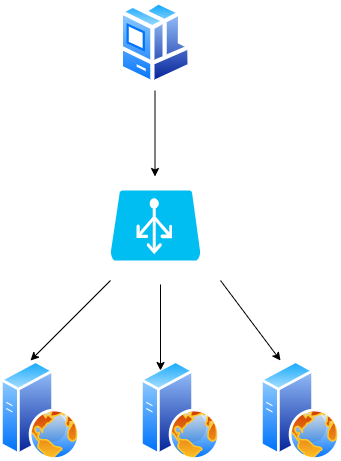
Czym jest load balancer? Jest usługą, która za pomocą odpowiednich algorytmów potrafi przekazać żądanie klienta do serwera, który jest najmniej obciążony lub do kolejnego na liście. Może nawet przekazać żądanie konkretnego klienta za każdym razem do tego samego serwera.
Poza usługami dostępnymi w chmurze, load balancer jest możliwy do skonfigurowania lokalnie, przy pomocy np. HAProxy oraz Nginx.
Technika równoważenia obciążenia jest metodologią zapewniania odporności na uszkodzenia i poprawia dostępność w następujący sposób:
- W przypadku awarii głównego serwera, jego obciążenie przejmują serwer 2 i serwer 3. Witryna nie przejdzie w tryb offline. Musisz również dodać nowy, sprawny serwer do puli serwerów, aby zrównoważyć obciążenie.
- Gdy ruch szybko rośnie, wystarczy dodać więcej serwerów do puli serwerów WWW, a system równoważenia obciążenia przekieruje ruch za Ciebie.
Systemy równoważenia obciążenia wykorzystują różne zasady i algorytmy dystrybucyjne, aby optymalnie rozłożyć obciążenie w następujący sposób:
- Round robin – w tym przypadku każdy serwer otrzymuje żądania w kolejności sekwencyjnej pierwszego weszło, pierwsze wyszło (FIFO).
- Least number of connections (najmniejsza liczba połączeń) – serwer z najmniejszą liczbą połączeń zostanie skierowany do odebrania żądania.
- Fastest response time (najszybszy czas odpowiedzi) – serwer, który ma najkrótszy czas odpowiedzi (ostatnio lub często), zostanie skierowany do odebrania żądania.
- Weighted (ważona) – mocniejsze serwery otrzymają więcej żądań niż słabsze, strategia niedoważenia.
- Hash IP – obliczany jest skrót adresu IP klienta w celu przekierowania żądania do serwera.
Programowy load balancer jest tanią alternatywą dla sprzętowych rozwiązań tego typu. Działa w warstwie 4 (warstwa sieciowa) i warstwie 7 (warstwa aplikacji).
- Warstwa 4 – system równoważenia obciążenia wykorzystuje informacje dostarczane przez TCP w warstwie sieci.
- Warstwa 7 – żądania mogą być równoważone na podstawie informacji w ciągu zapytania, plików cookie lub dowolnego wybranego przez nas nagłówka, a także zwykłych informacji o warstwie, w tym adresów źródłowych i docelowych.
Skalowanie relacyjnej bazy danych
Za pomocą prostego systemu możemy użyć RDBMS, takiego jak Oracle lub MySQL, do zapisywania elementów danych. Jednak systemy relacyjnych baz danych wiążą się z wyzwaniami, zwłaszcza gdy musimy je skalować.
Istnieje wiele technik skalowania relacyjnej bazy danych: replikacja master-slave, replikacja master-master, federacja, sharding, denormalizacja i strojenie SQL.
- Replication (replikacja) – zwykle odnosi się do techniki, która pozwala nam przechowywać wiele kopii tych samych danych na różnych komputerach.
- Federation (federacja) – (lub partycjonowanie funkcjonalne) dzieli bazy danych według funkcji.
- Fragmentacja (sharding) – to wzorzec architektury bazy danych związany z partycjonowaniem poprzez umieszczanie różnych części danych na różnych serwerach, a inny użytkownik będzie miał dostęp do różnych części zbioru danych
- Denormalization (denormalizacja) próbuje poprawić wydajność odczytu kosztem wydajności zapisu poprzez skopiowanie danych, które są zapisywane w wielu tabelach, aby uniknąć kosztownych łączeń.
- Strojenie SQL (SQL tuning).
Replikacja master-slave
Technika replikacji typu master-slave umożliwia replikację danych z jednego serwera bazy danych (master) na jeden lub więcej innych serwerów bazy danych (slave), jak na poniższym rysunku.
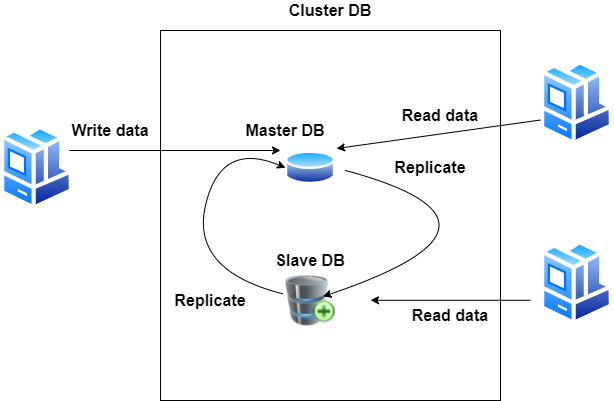
Powyższy schemat tworzy skalowalne środowisko bazy danych. Takie podejście pozwala na zabezpieczenie danych przed ich utratą, najważniejszym elementem jest replikowanie fragmentów danych, które tworzą całościowy obraz bazy. Użytkownicy mogą pracować na danych bez znaczenia czy jest to baza master czy też slave, w obydwu dane zachowują spójność. Dla użytkownika czy aplikacji taki klaster jest przeźroczysty, ważne aby 1 instancja master bazy działała.
Takie rozwiązanie ma jednak minusy:
- Jeśli serwer główny ulegnie awarii z jakiegokolwiek powodu, dane będą nadal dostępne za pośrednictwem urządzenia podrzędnego, ale nowe zapisy nie będą możliwe.
- Potrzebujemy dodatkowego algorytmu, aby awansować instację slave na master.
Oto kilka rozwiązań, dzięki którym tylko jeden serwer może obsługiwać żądania aktualizacji:
- Synchronous solutions (rozwiązanie synchroniczne) – transakcja modyfikująca dane nie jest zatwierdzana, dopóki nie zostanie zaakceptowana przez wszystkie serwery (transakcja rozproszona), dzięki czemu żadne dane nie zostaną utracone podczas przełączania awaryjnego.
- Asynchronous solutions (rozwiązania asynchroniczne) – zapis -> opóźnienie -> transfer na inne serwery w klastrze, więc niektóre aktualizacje danych mogą zostać utracone podczas przełączania awaryjnego.
Jeśli rozwiązania synchroniczne są zbyt wolne, zmień je na rozwiązania asynchroniczne.
Replikacja master-master
Każdy serwer bazy danych może działać jako master w tym samym czasie, gdy inne serwery są traktowane jako master. W pewnym momencie wszystkie mastery synchronizują się, aby upewnić się, że wszystkie mają poprawne i aktualne dane.
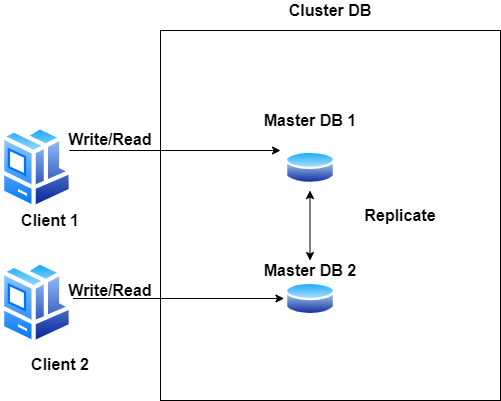
Oto kilka zalet replikacji master-master:
- Jeśli jeden master ulegnie awarii, pozostałe serwery bazy danych mogą działać normalnie. Gdy serwer bazy danych będzie ponownie w trybie online, nadrobi zaległości przy użyciu replikacji.
- Tryb master-master pozwala na działanie serwerów w kilku fizycznych lokalizacjach.
Ograniczone przez zdolność mastera do przetwarzania aktualizacji.
Federacja
Federacja (lub partycjonowanie funkcjonalne) dzieli bazy danych według funkcji. Zamiast jednej, monolitycznej bazy danych, można mieć trzy bazy danych: users, products i groups, co skutkuje mniejszym ruchem odczytu i zapisu w każdej bazie danych, a tym samym mniejszym opóźnieniem replikacji.
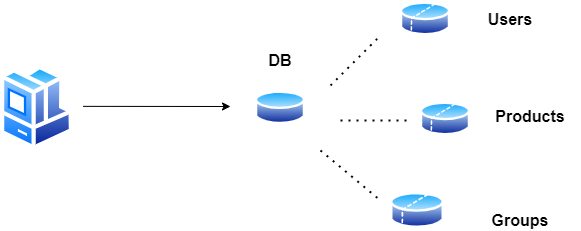
Mniejsze bazy danych dają więcej danych, które można zmieścić w pamięci podręcznej. Bez jednego centralnego mastera serializującego zapisy można pisać równolegle, zwiększając przepustowość.
Sharding (partycjonowanie danych)
Sharding (znany również jako partycjonowanie danych) to technika dzielenia dużej bazy danych na wiele mniejszych części, tak aby każda baza danych mogła zarządzać tylko podzbiorem danych.
W idealnym świecie wszyscy użytkownicy komunikują z różnymi węzłami bazy danych. Pomaga to poprawić łatwość zarządzania, wydajność, dostępność i równoważenie obciążenia systemu.
Każdy użytkownik musi komunikować się tylko z jednym serwerem, dzięki czemu otrzymuje szybkie odpowiedzi z danymi z tego serwera.
- Obciążenie jest rozłożone między serwerami — na przykład, jeśli mamy pięć serwerów, każdy z nich musi obsłużyć tylko 20% obciążenia.
- W praktyce istnieje wiele różnych technik dzielenia bazy danych na wiele mniejszych części
Horizontal partitioning (Partycjonowanie poziome)
W tej technice umieszczamy różne wiersze w różnych tabelach. Na przykład, jeśli przechowujemy profile użytkowników w tabeli, możemy zdecydować, że użytkownicy z identyfikatorami mniejszymi niż 1000 są przechowywani w jednej tabeli, a użytkownicy z identyfikatorami większymi niż 1001 i mniejszym niż 2000 są przechowywani w drugiej etc.
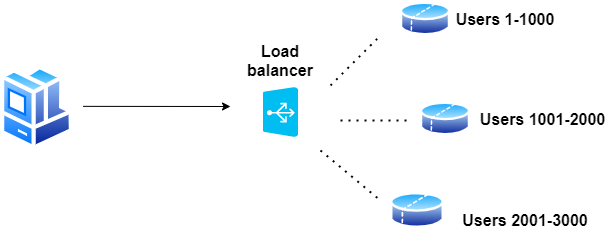
Vertical partitioning (Partycjonowanie pionowe)
W tym przypadku dzielimy nasze dane, aby przechowywać tabele związane z konkretną funkcją na własnym serwerze. Na przykład, jeśli budujemy system podobny do Facebook’a — w którym musimy przechowywać dane związane z użytkownikami, przesyłanymi przez nich zdjęciami i osobami, które śledzą — możemy zdecydować się na umieszczenie informacji o profilu użytkownika na jednym serwerze DB, listy znajomych na innym, i zdjęcia na trzecim serwerze.
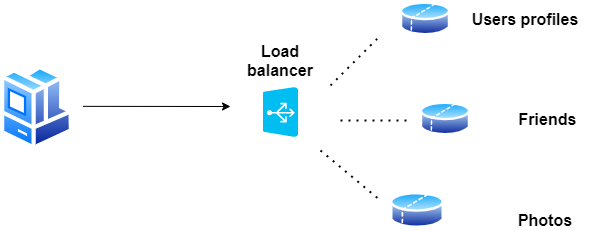
Partycjonowanie oparte na katalogach
Luźno powiązanym podejściem do tego problemu jest utworzenie usługi wyszukiwania, która zna bieżący schemat partycjonowania i przechowuje mapę każdej jednostki oraz fragmentu bazy danych, w którym jest przechowywana.
Tej metody można użyć, gdy magazyn danych prawdopodobnie będzie wymagał skalowania poza zasoby dostępne dla pojedynczego węzła magazynowania lub zwiększenia wydajności przez zmniejszenie rywalizacji w magazynie danych. Należy jednak pamiętać, że z technikami szeroko rozumianego shardingu występują następujące typowe problemy.
- Łączenia baz danych stają się droższe i w niektórych przypadkach niewykonalne.
- Fragmentowanie może naruszyć integralność referencyjną bazy danych.
- Zmiany schematu bazy danych mogą być bardzo kosztowne.
- Dystrybucja danych nie jest jednolita, a fragment jest bardzo obciążony.
Denormalizacja
Denormalizacja próbuje poprawić wydajność odczytu kosztem wydajności zapisu. Nadmiarowe kopie danych są zapisywane w wielu tabelach, aby uniknąć kosztownych łączeń.
Gdy dane zostaną rozprowadzone za pomocą technik, takich jak federacja i sharding, zarządzanie połączeniami w centrach danych jeszcze bardziej zwiększa złożoność. Denormalizacja może obejść potrzebę takich złożonych sprzężeń.
W większości systemów odczyty mogą znacznie przewyższyć liczbę zapisów 100:1 lub nawet 1000:1. Odczyt skutkujący złożonym dołączaniem do bazy danych może być bardzo kosztowny, powodując poświęcenie znacznej ilości czasu na operacje dyskowe. Niektóre RDBMS, takie jak PostgreSQL i Oracle, obsługują widoki zmaterializowane, które obsługują pracę polegającą na przechowywaniu nadmiarowych informacji i utrzymywaniu spójności nadmiarowych kopii.
Ryan Mack z Facebooka dzieli się sporą częścią historii implementacji Osi czasu w swoim artykule: Budowanie osi czasu: skalowanie, aby utrzymać swoją historię życia, dzięki wykorzystaniu właśnie denormalizacji.
Jakiej bazy danych użyć?
W świecie baz danych istnieją dwa główne typy rozwiązań: SQL i NoSQL. Różnią się sposobem przechowywania danych.
SQL
Relacyjne bazy danych przechowują dane w wierszach i kolumnach. Każdy wiersz zawiera wszystkie informacje o jednej jednostce, a każda kolumna zawiera wszystkie oddzielne punkty danych.
Niektóre z najpopularniejszych relacyjnych baz danych to MySQL, Oracle, MS SQL Server, SQLite, Postgres i MariaDB.
NoSQL
Nazwano także nierelacyjne bazy danych. Magazyny klucz-wartość, wykresy, kolumny, dokumenty i obiekty BLOB są elementami budowy tego typu baz.
Key-value
Dane są przechowywane w tablicy par klucz-wartość. „Klucz” to nazwa atrybutu połączona z „wartością”.

Znane bazy działające w tej technologi to Redis, Voldemort i Dynamo.
Document DBs
W tych bazach dane są przechowywane w dokumentach (zamiast wierszy i kolumn w tabeli), a dokumenty te są pogrupowane w kolekcje. Każdy dokument może mieć zupełnie inną strukturę.
Bazy danych dokumentów obejmują CouchDB i MongoDB.
Bazy szerokokolumnowe
Zamiast „tabel” w kolumnowych bazach danych mamy rodziny kolumn, które są kontenerami na wiersze. W przeciwieństwie do relacyjnych baz danych nie musimy znać z góry wszystkich kolumn, a każdy wiersz nie musi mieć takiej samej liczby kolumn.
Kolumnowe bazy danych najlepiej nadają się do analizy dużych zbiorów danych, przykładami są tutaj Cassandra i HBase.
Bazy „wykresowe”
Bazy te służą do przechowywania danych, których relacje są najlepiej reprezentowane na wykresie (graficznie). Dane zapisywane są w strukturach grafowych z węzłami (entycjami), właściwościami (informacjami o encjach) oraz liniami (połączeniami pomiędzy encjami).
Przykładami grafowych baz danych są Neo4J i InfiniteGraph.
Bazy Blob
Obiekty Blob przypominają bardziej magazyn key-value dla plików i są dostępne za pośrednictwem interfejsów API, takich jak Amazon S3, Windows Azure Blob Storage, Google Cloud Storage, Rackspace Cloud Files lub OpenStack Swift.
Zaawansowane koncepcje skalowania
Buforowanie (caching)
Równoważenie obciążenia (load balancing) pomaga skalować na coraz większej liczbie serwerów. Takie rozwiązanie umożliwia znacznie lepsze wykorzystanie zasobów, które już posiadasz. Infrastruktura jest w stanie znacznie szybciej przetwarzać dane, co ułatwia działanie organizacji.

Dodając cache do infrastruktury możemy uniknąć odczytywania strony internetowej lub danych bezpośrednio z serwera, zmniejszając w ten sposób zarówno czas odpowiedzi, jak i obciążenie naszego serwera. Pomaga to w zwiększeniu skalowalności naszej aplikacji.
Buforowanie można zastosować na wielu warstwach, takich jak warstwa bazy danych, warstwa serwera WWW i warstwa sieci.
Content Delivery Network (CDN)
Serwery CDN przechowują w pamięci podręcznej kopie treści (takich jak obrazy, strony internetowe itp.) i udostępniają je z najbliższej lokalizacji w stosunku to rezydowania klienta.
CDN zasadniczo skraca czas ładowania danych dla użytkowników. Rozwiązanie to zapewnia szybsze dostarczenie informacji do klienta. Dane dostarczane są sprawniej z rozproszonego środowiska niż z głównej siedziby na drugim końcu świata.
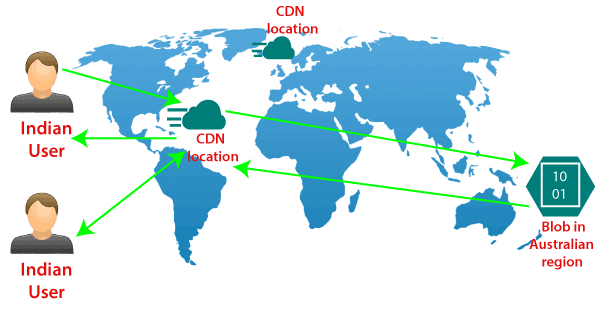
Serwery CDN wysyłają żądania do naszego serwera sieci Web, aby zweryfikować buforowaną zawartość i zaktualizować je, jeśli jest to wymagane. Zawartość buforowana jest zwykle statyczna, np. strony HTML, obrazy, pliki JavaScript, pliki CSS itp.
Globalizacja
Gdy Twoja aplikacja stanie się globalna, będziesz właścicielem i operatorem centrów danych na całym świecie, aby Twoje produkty działały 24 godziny na dobę, 7 dni w tygodniu. Krótko mówiąc zapytanie klienta „samo” szuka najlepszej lokalizacji do odpowiedzi.

GeoDNS to usługa DNS, która umożliwia rozwiązywanie nazw domen na adresy IP na podstawie lokalizacji klienta. Klient łączący się z USA może otrzymać inny adres IP niż klient łączący się z Europy.
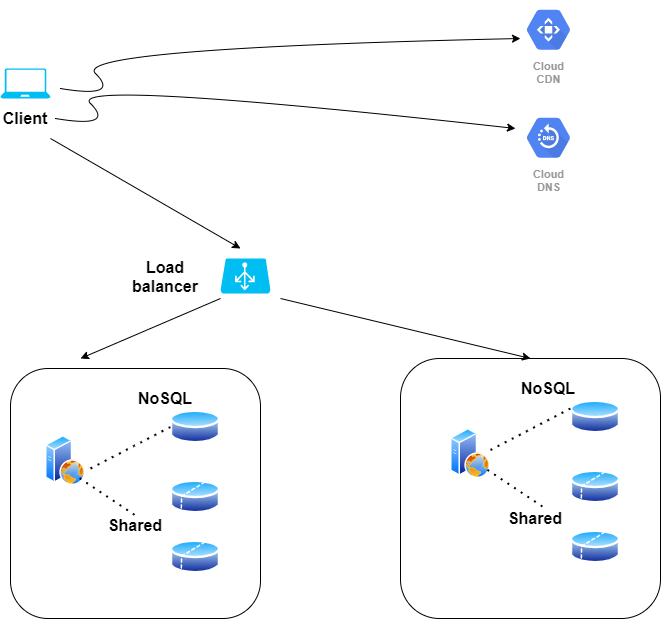
Powyżej schemat wdrożenia aplikacji dla klienta, który zapewnia wysoki poziom bezpieczeństwa, szybką dostawę danych oraz optymalizacje kosztów.
Podsumowanie
Chmura publiczna dziś daje możliwości, któych nie było 15 czy 20 lat temu. Pozwala rozwijać organizacje oraz dostarczać rozwiązanie dla każdego niezależnie od tego gdzie znajduje się jego klient. Optymalizuje koszty poprzez dostosowywanie ich do potrzeb w danej chwili. Jeżeli wymaga skalowania infrastruktury robi to automatycznie lub półautomatycznie, ale nadal o wiele wydajniej i sprawniej niż ma to miejsce przy lokalnych rozwiązaniach.
Dziękuję Ci, za poświęcony czas na przeczytanie tego artykułu. Jeśli był on dla Ciebie przydatny, to gorąco zachęcam Cię do zapisania się na mój newsletter, jeżeli jeszcze Cię tam nie ma. Proszę Cię także o “polubienie” mojego bloga na Facebooku oraz kanału na YouTube – pomoże mi to dotrzeć do nowych odbiorców. Raz w tygodniu (niedziela punkt 17.00) otrzymasz powiadomienia o nowych artykułach / projektach zanim staną się publiczne. Możesz również pozostawić całkowicie anonimowy pomysł na wpis/nagranie.
Link do formularza tutaj: https://beitadmin.pl/pomysly
Pozostaw również komentarz lub napisz do mnie wiadomość odpisuję na każdą, jeżeli Masz jakieś pytania:).
